How NVIDIA's Speculative Decoding Speeds Up RL Training for Large Language Models
Reinforcement learning (RL) post-training for large language models (LLMs) on reasoning tasks can be painfully slow—especially during rollout generation. A new approach from NVIDIA integrates speculative decoding directly into the NeMo RL training loop, delivering lossless acceleration without altering the model's output distribution. This Q&A breaks down the key findings, including speedup numbers, system integration challenges, and why this technique is a game-changer for RL training. Jump to the bottleneck analysis or see speedup benchmarks.
What is the main bottleneck in RL post-training for LLMs?
In synchronous RL training, each step involves five stages: data loading, weight synchronization and backend preparation (prepare), rollout generation (gen), log-probability recomputation (logprob), and policy optimization (train). NVIDIA researchers measured these stages on Qwen3-8B under two workloads—RL-Think (continuing a reasoning model) and RL-Zero (learning reasoning from scratch). In both cases, rollout generation consumes 65–72% of the total step time. Log-probability recomputation and training together account for only 27–33%. This makes rollout generation the dominant bottleneck—and the most impactful target for acceleration. Any optimization to the generation stage directly determines the upper bound for overall training speed.
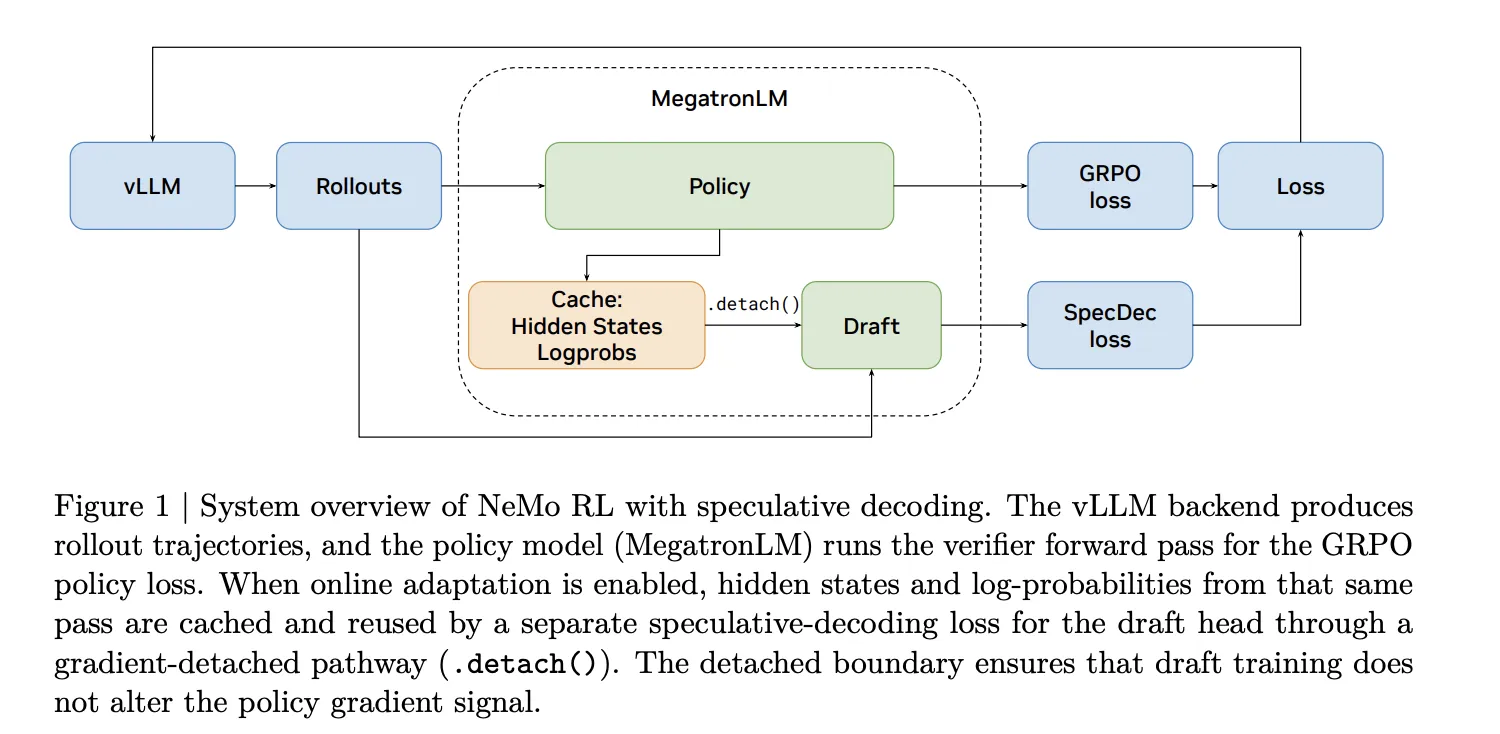
How does speculative decoding work in the context of RL training?
Speculative decoding uses a smaller, faster draft model to propose several tokens at once. The larger target model—the one being trained—then verifies those tokens using a rejection sampling procedure. Crucially, this verification is mathematically guaranteed to produce the exact same output distribution as if the target model had generated each token one by one (autoregressively). In RL training, this means no distribution mismatch, no off-policy corrections, and no change to the training signal. The rollouts are identical in distribution to what the target model would have produced on its own—just generated faster. This is a key advantage over methods like asynchronous execution or low-precision rollouts, which trade training fidelity for speed.
Why is preserving the exact output distribution important for RL?
In RL post-training, the reward signal depends directly on the policy's own generated samples. If the rollout distribution differs from the target model's true distribution (e.g., due to approximation or off-policy sampling), the training signal becomes biased. Methods like asynchronous execution, off-policy replay, or low-precision rollouts all trade some amount of training fidelity for throughput—they may speed things up but at the cost of introducing distribution mismatch. Speculative decoding, by contrast, trades nothing: the rollouts are statistically identical to what the target model would have generated on its own, just produced faster. This preserves the integrity of the RL training loop, ensuring that the policy learns from correct, on-policy samples.
What speedups did NVIDIA achieve at different model scales?
The research team integrated speculative decoding into NeMo RL v0.6.0 with a vLLM backend and measured rollout generation speedups. At the 8B parameter scale, they observed a 1.8× speedup in rollout generation throughput. For larger models, they project even greater gains: at the 235B scale, the estimated end-to-end training speedup reaches approximately 2.5×. These improvements are lossless—they come without any degradation in the target model's output distribution or training quality. The key insight is that as model size grows, the overhead of running the draft model becomes relatively smaller compared to the target model's verification step, making speculative decoding more efficient at scale.
What are the challenges of adding speculative decoding to RL training?
Integrating speculative decoding into a serving backend (like vLLM for inference) is relatively straightforward. But adding it to an RL training loop is far more complex. The main challenge is that every time the policy updates, the rollout engine must receive new weights. The draft model must also be updated to stay consistent with the evolving target model—otherwise, its proposals become increasingly misaligned. NVIDIA's solution involves careful weight synchronization and backend management to ensure both models are always in sync. They also had to handle the prepare stage (weight synchronization and backend setup) efficiently, since any delay there could offset the gains from faster generation. The result is a seamless integration that works within the existing NeMo RL pipeline.
What other features ship in NeMo RL v0.6.0?
Beyond speculative decoding, the NeMo RL v0.6.0 release includes several other notable features: the SGLang backend as an alternative to vLLM for rollout generation, the Muon optimizer (a memory-efficient optimizer for large-scale training), and YaRN long-context training (supporting models with extended context windows). These additions complement speculative decoding to further improve training efficiency and flexibility. The Muon optimizer, in particular, helps reduce memory footprint, while YaRN enables training on longer sequences—useful for reasoning tasks that require multi-step chains. Together, these features make NeMo RL v0.6.0 a comprehensive toolkit for RL post-training on large language models.